Why Coupling and Cohesion Is a Term Product and Delivery Need to Understand Deeply Too!
Coupling and Cohesion
We work in a world where we build things that need to change and they need to change in ways we cannot really know yet, Because of this our primary design goal at all levels is to be able to make changes - therefor when we have systems that are hard to change we know our designs could improve.
This means our delivery, product and technical designs all can have the same ideas and principles applied to achieve slightly different practices and understanding - but all be connected by the same framework.
We say good design is highly cohesive with low coupling but what does this mean and how is it helpful? It is simply the statement that if i want to change 1 thing I should not have to change many things.
Bad design is where in order to make 1 change I have to change many (or all) systems under it. There are many reasons this is bad - for example
- if multiple systems are required to validate, then the validation of each systems work-is-done can only occur after the whole is done (this is a circular dependency that resolves into defective work)
- change may be required in places we do not know - because we do not know what has coupled to what.
- Sequences of change produce increases in lead time, and due to chance of requirement change, also increase the chance of obsolescence before value extraction.

But the power of talking about coupling is that we are in control of how it is managed and there are moves we can make to change it - this is the art of refactoring. Traditionally this applies to code, but I find the concepts carry very well to product and delivery and I want to share this powerful tool.
This post will talk about this and show some examples of how moves can be made. The point here is that when we think about things in abstract we find that ideas from one domain readily apply to another.
Do you want to work with
this:
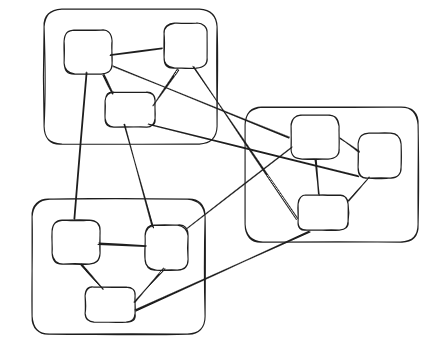
or:
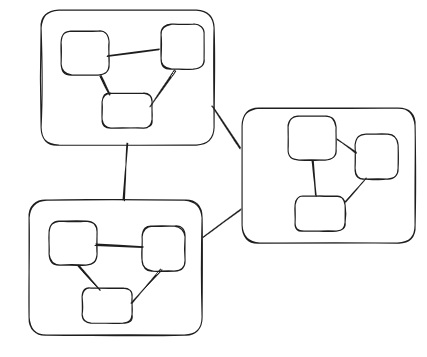
In the first if you make a change to anything it is connected to everything - how do we know what actually has to change? I cannot tell you that, however I can tell you how to refactor the system into the second diagram and now that question becomes simple!
Why is nobody talking about this in delivery and product?
Coupling
In code we have Connascence which is a categorisation of types of coupling - part of what I am trying to do is accomplish the same thing in other spaces. Different spaces will have different categorisations - but some of them carry.
Coupling has at minimum 3 dimensions
- Type - this is how it is coupled.
- For example, access to a bank account is coupled to the value of a pin number.
- Being able to do secure transaction is coupled to encryption algorithms, we name them so that we have an easier time.
- In plumbing, it might be the type of pipe.
- In delivery, it might be the different features into multiple teams that need to line up for a release
- In product it is how a change to influence a customer flows through teams.
- In engineering, it is how 1 change causes changes in multiple systems.
- The type of coupling determines how hard it is to detect and so test the change. Some forms of coupling can be identified visually, others can only be discovered over time.
- So we can use type of coupling to have conversations about how to change to easier to manage forms of coupling.
- In code if someone says x is coupled to Y by Z then I can list the types of refactor you can use to transform z into a simpler form.
We should be able to do the same in other areas - if as an engineer you cannot do this, you are missing a trick!
- Locality - this is how far away the coupled things are.
- Things that are close together are easy to spot.
- When we change things and have a surprise because something else is coupled, then it is far away.
- EG deploying code fails to run sometimes because of a switch in a datacenter - which has nothing to do with anything with deploying the code. When this fails it is exceptionally hard to identify as it was unnrelated to any action - this is locality.
We will come back to locality when we talk about cohesion
- Degree - this is the number of things that are coupled.
- The more things, then the harder it is to change because more has to be managed.
- Degree matters because often we care about coupling when surprises happen, and so we add a new thing to the list of coupled things.
- If many things always change at the same time - are they really many things? (again will come back to this in cohesion)
So when we are manipulating coupling we talk about changing the type of coupling, bringing things closer and further apart to change locality and finally, redefining boundaries to increase or reduce the degree of coupling.
So coupling is about webbyness, and how things are connected, but what is cohesion?
Cohesion
Cohesion ends up being a qualitive term that describes how easy and risk-free it is to work with something. The higher the cohesion to easier and safer it is to work with something. Things that are not safe to work with cause suprises. Suprise is when we discover at run time (ie production) that 2 things are coupled unexpectedly - this is a demonstration of low cohesion. We fix this by changing the system to increase its cohesion via changing that form of coupling from runtime into something more explicit. Maybe we document it, maybe we change who owns something.
Yak shaving, eg needing to change a lightbulb but ends up with you in a DIY store buying paint and a chainsaw is an example of low cohesion - lots of different things connected up to get you there because they were all coupled in wierd hard to see and predict ways.
This is the problem of low cohesion - when things are vague and wooley, when work spreads out into systems then things become incredibly complex to manage and maintain a mental model of. The result is that failure is inevitable and the cycles to fix tremendously expensive.
Essentially whenever we make a change to a coupled system we will be looking to increase cohesion. We want to bring multiple things that change together closer together.
We can ask is it always good to increase cohesion? When might it be good to lower it?
There are times when we might lower cohesion - in systems that have become overly formal in a way that is bad (eg bad team structures) we might act to remove the constraints between them so that they can mingle and we can look for a different structure to emerge to form cohesion and rules around. These choices are almost always around trying to find new and novel ways.
Uses and examples of coupling and cohesion
Eg that microservice with 8 teams all needing to deploy for something to be tested (yes, you know who you are!)… refactor it into (potentially 1 team with) a mono-repository and tests that can be run by all at once. Increase the cohesion by bringing the coupling closer together. This then reduces the number of things external things are coupled to (it is now 1 thing), which means internally it is now far easier to change the types of coupling at play. The result is a highly cohesive code base - all those things that exist to manage the coupling between 8 teams can go away and instead time can be invested on the contract of the 1 codebase with the rest of the system.
This is a strategy that is supremley powerful.
Low cohesion systems resolve into high cohesion at runtime
We use things, things have boundaries. When we have a low cohesion system what this means is that when we are working with it we are forced to work with all the bits it has spread into.
In delivery this means that we cannot release team A without teams b through z - we may feed work into them seperatley but the unit of deployment is the whole and so the velocity of the delivery process is the slowest part
In delivery this also means if you create an external test team at service level the velocity of the entire program will be the velocity of the test team - not the many ‘scaled’ teams feeding it. I cannot comprehend why I still see deliveries deliberatley setup like this.
In product this means that if you haven’t found ways to isolate value streams that provide different kinds of users different kinds of value then any change you do will hit every system because the system will be partitioned by technology - not user / customer. This will mean that nobody is also tracking anything you care about by design - which means the system is not designed around anything you care about either.
In produdt if you do not identify that you want to be able to release to subsets of users then there is no design pressure to make tech behave and build a deployment pipeline that enables this - as a result behaviour will become coupled to deployments and experimentation will become all but impossible (or highly expensive to implement)
When the above things are not in place it them becomes exceptionally easy for people to start to sell in products that becomes layers and so our architectures by design are low cohesion and highly coupled with respect to the above problems. The result is blindingly obvious and inevitable - and it all comes from people neglecting their responsibilities to provide highly cohesive designs that have low coupling.
All of these systems will resolve into highly cohesive systems by virtue of the fact that to do anything then everything has to move in lockstep. This is tremendously expensive.
However, in my world, many product and delivery people don’t recognise those problems and so cannot recognise that their solutions lack cohesion and drive the problem of technology layers but do recognise that nobody in the tech layers can get any work done. It must be a tech problem!
Another example:
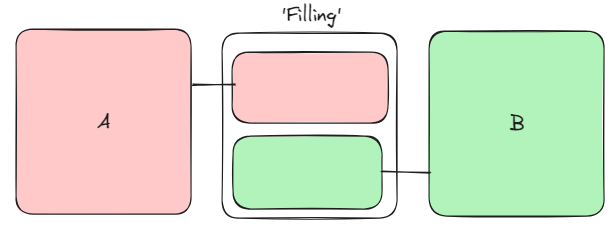
This diagram shows an example of 3 things. A, B and the filling. Here the drawing is showing that when A changes so does the red part of filling, and when B changes so does the green part of filling. The change flows from A and B into filling.
This means we can say filling is coupled to 2 things, we do not know how they are coupled nor the distance, but doesn’t matter here.
In this system if these are 3 teams, then teams A + B are dependent on the middle team - this means that with this design one of those teams will suffer a delay whilst the other is working. This is necessary because team B has to queue behind team A wanting to use ‘Filling’.
If this was code and a codebase we would refactor filler potentially in a number of ways
- by moving the red code into the red side and the green code into the green side.
- by splitting filler into 2 separate objects
- Maybe we realise that everytime red changes then green also changes and so this entire thing is really 1 thing, and we are looking at the wrong level of abstraction
Why does this matter so much with teams? It is because this kind of coupling means that A + B are coupled together (despite ostensibly perhaps not being related) and also suffer low cohesion with Filler. It means that for the system to resolve into something highly cohesive - ie a unit of delivery we cannot consider team A or team B on their own. Those teams are not cohesive - we have to consider team A with respect to teams B and Filler.
It might not be obvious but if say B was coupled to C by a similar arrangement that would mean that A would also be coupled to C - simply because A is coupled to B. There are ways to break this transitivity - but if we work with people making the ‘filler’ mistake they are not going to have the maturity to spot, identify and manage coupling at even lower localities. As a result their systems will fail.
This is bad design because the entire point of teams is to enable scalability of work - which implies the ability of teams to work independently. This is a system that has designed in an dependency. We cannot accept this kind of laxadazy attitude and need to find better ways of designing these relationships.
It follows from this that the release cadence of team A is the release cadence of team Filler. The release cadence of team B is also the cadence of Filler, and Filler is the cadence of Filler.
This means that to get performance benefit from Team A the answer is actually to optomise Filler and leave team A alone.
How to Fix - We Extract + Move Method
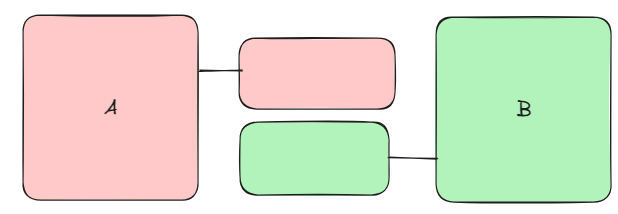
We fix this problem by using an extract method refactor to the teams. We take the red work filler was doing, we wrap it up in a job (name it), and then move that job into team A. We repeat again for the green work into team B.
Now filler no longer exists and both A and B are no longer coupled. These teams can now release independently and work at their own cadence without being constrained by team Filler.
Summary
We all have a responsibility to understand coupling and cohesion and how to apply it to our various roles.
Once we get these ideas and can use them we get to ask interesting questions like ‘cohesive to what end?’
So many problems can be related back to these ideas because at the of the day everything is boxes and lines.
So I ask again, do you want to work with
or
I think the answer is blindingly obvious - but everytime we don’t put in the work to refactor systems into these shapes we pay the price.
Technical Debt in engineering is not managing this, this debt exists in product and delivery too. But because these roles do not contain the analytical people to recognise it the cost of it is also unrecognised.
If instead of spending our time arguing about scrum / safe / scope / deadlines / overtime we actually spent time analysing our systems, finding and fixing coupling and cohesion problems we would probably stop caring so much.